Google’s parent company, Alphabet, has found itself in the news after their not-yet-released AI chatbot, Bard, gave an incorrect answer to a prompt during its initial demo.
This is generating buzz within the tech community, which causes us to pause and assess the veracity of answers given by AI chatbots and how heavily we can truly rely on these tools.
Google’s Chatbot’s Major Error
In the chatbot’s demo, recently posted by Google on Twitter, a user poses the question: “What new discoveries from the James Webb Space Telescope can I tell my 9 year old about?” Bard’s response, pictured, includes a major factual error.

The James Webb Space Telescope did not, in fact, take the first pictures of an exoplanet, so the answer is incorrect.
As a result of this blunder, shares in Google’s parent company Alphabet dropped more than 7%, a total loss of $100 billion of the enterprise’s market capitalization.
However, it’s important to note that the design goal of a chatbot is not to be correct. It is to be plausible; it is to match patterns from its training data, it is to be creative.
Experimenting with Large Language Models (LLMs)
At AIM’s 2022 internal technology summit, the community of AIMers gained hands-on experience building out an AI and language model. We used data tools to train language generation that wrote text in the style provided to the training engine.
When we trained the engine on the works of Edgar Alan Poe, the model generated creepy foreboding text. When it was trained on Alice’s Adventures in Wonderland, it generated whimsical and surreal text. But in all cases, the text was mildly plausible nonsense. The body of training data for our experiments was too small.
In systems like Google’s Bard or ChatGPT or the new Bing, they use what is known as a Large Language Model or LLM, in which the system is trained on a much larger body of text, thousands or millions of times larger.
The results that are produced by these LLM systems are more well-formed and are closer to the patterns in the large body of training data, but they are not designed for correctness. Getting the right answer to a factual question is simply not part of its requirements.
How Accurate is ChatGPT?
In using ChatGPT, we found that it is excellent at open-ended questions like “where is a good place to take my family on vacation?” But when presenting a factual query “Where can I stream everybody’s going to the world’s fair” to find out where to go to watch a movie, it gave answers that were incredibly wrong.
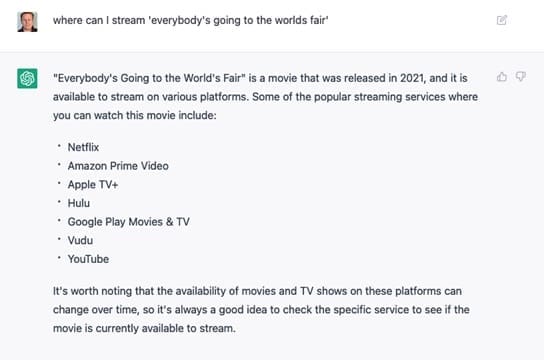
First of all, the title was incorrect in the prompt sent to ChatGPT. The correct title of the movie I was looking for is “We’re All Going to the World’s Fair,” but the chatbot happily gave information on the real movie, claiming it was information on the title we requested.
Furthermore, ChatGPT advised watching the movie on a selection of streaming services including Netflix, Hulu, and YouTube.
The problem is that the movie is not available on Hulu, Netflix, or YouTube. None of the services that ChatGPT noted include the title in their subscriptions; it is only available to stream on HBO Max.
When the prompt was later repeated, it did a better job and at least noted where the movie could be likely rented instead of providing an apparently random selection of plausible streaming services.
The way that an LLM chatbot continuously improves is remarkable, and its information will trend in the direction of correctness, but it absolutely cannot be depended on. There is simply no mechanism in a large language model for concrete verification.
In another AI experiment, we performed testing last year on GitHub Copilot. That tool often gave plausible-looking code that was not able to even compile or run.
The AI did pattern matching on what good code looks like, but was unable to know if that great-looking code was correct enough to even execute.
The Right Expectations for AI Chatbots
So it should be unsurprising that the Google LLM chat engine was incorrect when it claimed that the James Webb Telescope took the first picture of an exoplanet.
With some feedback, it’s likely the chatbot engine could even give an answer next time that’s closer to correct.
But a large language model alone cannot be depended on for correctness. It will always give verbose, correct-sounding answers to the questions you give.
At AIM Consulting, we bring deep experience and pragmatic solutions to challenges across multiple technologies including Data and AI. Learn more about our solutions to find out how AIM can help tackle your most challenging projects and empower your organization’s growth and success.
Insights By

Need Help Leveraging Artificial Intelligence?
We are technology consulting experts & subject-matter thought leaders who have come together to form a consulting community that delivers unparalleled value to our client partners.